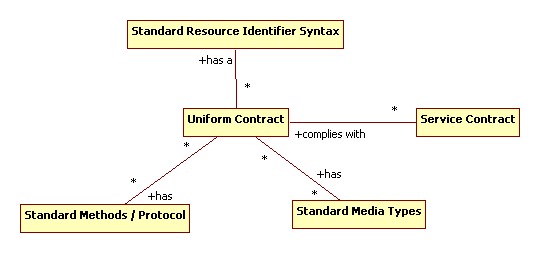
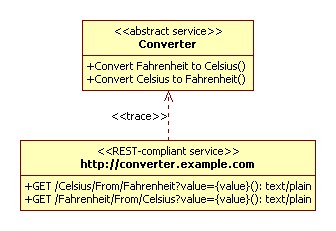
REST is the architectural style of the Web, and closely related to REST is the concept of a HTTP API. A HTTP API is a programmer-oriented interface to a specific service, and is known by other names such as a RESTful service contract, resource-oriented architecture, or a URI Space.
I say closely related because most HTTP APIs do not comply with the uniform interface constraint in it's strictest sense, which would demand that the interface be "standard" - or in practice: Consistent enough between different services that clients and services can obtain significant network effects. I won't dwell on this!
One thing we know is that these APIs will change, so what can we do at a technical level to deal with these changes as they occur?
The Moving Parts
The main moving parts of a HTTP API are
- The generic semantics of methods used in the API, including exceptional conditions and other metadata
- The generic semantics of media types used in the API, including any and all schema information
- The set of URIs that make up the API, including specific semantics each generic method and generic media types used in the API
These parts move at different rates. The set of methods in use tend to change the least. The standard HTTP GET, PUT, DELETE, and POST are sufficient to perform most patterns of interactions that may be required between clients and servers. The set of media types and associated schema change at a faster rate. These are less likely to be completely standard, so will often include local jargon that changes at a relatively high rate. The fastest changing component of the API is detailed definition of what each method and media type combination will do when invoked on the various URLs that make up the service contract itself.
Types of mismatches
For any particular interaction between client and server, the following combinations are possible:
- The server and client are both built against a matching version of the API
- The server is built against a newer version of the API than the client is
- The client is built against a newer version of the API than the server is
In the first case of a match between the client and server versions, then there is no compatibility issue to deal with. The second case is a backwards- compatibility issue, where the new server must continue to work with old clients, at least until all of the old clients that matter are upgraded or retired.
Although the first two cases are the most common, the standard nature of methods and media types across multiple services means that the third combination is also possible. The client may be built against the latest version of the API, while an old service or an old server may end up processing the request. This is a forwards-compatibility issue, where the old server has to deal with a message that complies with a future version of the API.
Method Evolution
Adding Methods and Status
The addition of a new method may be needed under the uniform interface constraint to support new types of client/server interactions within the architecture. For HTTP these will likely be any type of interaction that inherently breaks one or more other REST constraints, such as the stateless constraint. However, new methods may be introduced for other reasons such as to improve the efficiency of an interaction.
Adding new methods does not impact backwards-compatibility, because old clients will not invoke the new method. It does impact forwards-compatibility because new clients will wish to invoke the new method on old servers. Additionally, changes to existing methods such as adding a new HTTP status code for a new exceptional condition can break backwards-compatibility by returning a message an old client does not understand.
Best Practice 1: Services should return 501 Not Implemented if they do not recognise the method name in a request
Best Practice 2: Clients that use a method that may not be understood by all services yet should handle 501 Not Implemented by choosing an alternative way of invoking the operation, or raising an exception towards their user in the case that no means of invoking the required operation now exists
Best Practice 3: A new method name should be chosen for a method that is not forwards-compatible with any existing method - i.e. a new method name should be chosen if the new features of the method must be understood for the method to be processed correctly (must understand semantics)
These best practice items deal with a new client that makes a request on and old server. If the server doesn't understand the new request method, it responds with a standard exception code that the client can use to switch to fallback logic or raise a specific error to their user. For example:
Client: SUBSCRIBE /foo Server: 501 Not Implemented Client: (falling back to a period poll) GET /foo Server: 200 OK
or
Client: LOCK /foo Server: 501 Not Implemented Client: (unable to safely perform its operation, raises an exception)
Best Practice 4: Services should ignore headers they do not understand or the components of which they do not understand. Proxies should pass these headers on without modification or the components they do not understand without modification.
Best Practice 5: The existing method name should be retained and new headers or components of headers added when a new method is forwards-compatible with an existing method
These best practice items deal with a new client that makes a request on an old server, but the new features of the method are a refinement of the existing method such as a new efficiency improvement. If the server doesn't understand the new nuances of the request it will treat it as if it were the existing legacy request, and although it may perform suboptimally will still produce a correct result.
Best Practice 6: Clients should handle unknown exception codes based on the numeric range they fall within
Best Practice 7: A new status should be assigned a status code within a numeric range that identifies a coarse-grained understanding of the condition that already exists
Best Practice 8: Clients should ignore headers they do not understand or the components of which they do not understand. Proxies should pass these headers on without modification or the components they do not understand without modification
Best Practice 9: If a new status is a subset of an existing status other than 400 Bad Request or 500 Internal Server Error then refine the meaning of the existing status by adding information to response headers rather than assigning a new status code.
These best practice items deal with a new server sending a new status to the client, such as a new exception.
Removing Methods and Status
Removing an existing method introduces a backwards compatibility problem where clients will continue to request the old method. This has essentially the same behaviour as adding a new method to a client implementation that is not understood by an old service, with the special property that the client is less likely to have correct facilities for dealing with the 501 Not Implemented exception. Thus, methods should be removed with care and only after surveying the population of clients to ensure no ill effects will result.
Removing an existing status within a new client implementation before all server implementations have stopped using the code or variant has similar properties to adding a new status. The same best practice items apply.
Media Type Evolution
Adding Information
Adding information conveyed in media types and their related schemas has an impact on the relationship between the sender of the document and the recipient of the document. Unlike methods and status which are asymmetrical between client and server, media types are generally suitable to travel in either direction as the payload of a request or response. For this reason in this section we won't talk about client and server, but of sender and recipient.
Adding information to the universe of discourse between sender and recipient of documents means either modifying the schema of an existing media type, or introducing a new media type to carry the new information.
Best Practice 10: Document recipients should ignore document content that they do not understand. Proxies and databases should pass this content on without modification.
Best Practice 11: Validation of documents that might fail to meet Best Practice item 10 should only occur if the validation logic is written to the same version of the API as the sender of the document, or a later version of the API
Best Practice 12: If the new information can be added to the schema of an existing media type in alignment with the design objectives of that media type then it should so added
For XML media types this means that recipients processing a given document should treat unexpected elements and attributes in the document as if they were not present. This includes the validation stage, so an old recipient shouldn't discard a document just because it has new elements in it that were not present at the time its validation logic was designed. The validation logic needs to be:
- Performed on the sender side, rather than the recipient side
- Performed on the recipient side only if the document indicates a version number that the recipient knows is equal to or older than its validation logic, or
- Performed on the recipient side only after it has checked to ensure its validation logic is up to date based on the latest version of the media type specification
With these best practice items in place, new information can be added to media type schemas and to corresponding documents. Old recipients will ignore the new information and new recipients are able to make use of it as appropriate. Note that information can still only be added to schemas in ways consistent with the "ignore" rules of existing recipients. If the ignore rule is to treat unknown attributes and elements as if they do not exist, then new extensions must be in the form of new attributes and elements. If they cannot be made in compliance with the existing ignore rules then the change becomes incompatible as per the next few Best Practice items.
Best Practice 13: Clients should support a range of current and recently-superseded media types in response messages, and should always state the media types they can accept as part of the "Accept" header in requests
Best Practice 14: Services should support returning a range of current and recently-superseded media types based on the Accept header supplied by its clients, and should state the actual returned media type in the Content-Type header
Best Practice 15: Clients should always state the media type they have included within any request message in the Content-Type header
Best Practice 16: Services that do not understand the media type supplied in a client request message should return 415 Unsupported Media Type and should include an Accept header stating the types they do support.
Best Practice 17: Clients that see a 415 Unsupported Media Type response should retry their request with a range of current and recently-superseded media types with due heed to the server-supplied Accept header if one is provided, before giving up and raising an exception towards their user.
Content negotiation is the mechanism that HTTP APIs use to make backwards-incompatible media type schema changes. The new media type with the backwards-incompatible changes in its schema is requested by or supplied by new clients. The old media type continues to be requested by and supplied by old clients. It is necessary for recent media types to be supported on the client and server sides until all important corresponding implementations have upgraded to the current set of media types.
Removing Information
Removing information from media types is generally a backwards-incompatible change. It can be done with care by deprecating the information over time until no important implementations continue to depend upon the information. Often the reason for a removal is that it has been superseded by a newer form of the information elsewhere, which will have resulted in information being added in the form of a new media type that supersedes one or more existing types.
URI Space Evolution
Adding Resources or Capabilities
Adding a resource is a service-specific thing to do. No longer are we dealing with a generic method or media type, but a specific URL with specific semantics when used with the various generic methods. Some people think of the URI space being something that is defined in a tree that is separate to the semantics of operations upon those resources. I tend to take a very server-centric view in thinking of it a service contract that looks something like:
- GET /invoice/{invoice-id}, returns application/invoice+xml, Return the invoice denoted by invoice-id
- GET /invoice/{invoice-id}/paid, returns text/plain (xsd:bool syntax), Return the invoice paid status for the invoice denoted by invoice-id
- PUT /invoice/{invoice-id}/paid, accepts text/plain (xsd:bool syntax), Set the invoice paid status for the invoice denoted by invoice-id
Adding new URIs (or more generally, URI Templates) to a service, or adding new methods to be supported for an existing URI do not introduce any compatibility issues. This is because each service is free to structure it resource identifiers in any way it sees fit, so long as clients don't start embedding (too many) URI templates into their logic. Instead, they should use hyperlinks to feel their way around a particular service's URI space wherever possible.
However, this can still become a compatibility issue between instances of a service. If it takes 30 minutes to deploy the update to all servers worldwide then there may well be client out there that are flip flopping between an upgraded server and an old server from one request to the next. This could lead to the client directed to use the new resources, but having their request end up at a server that does not support the new request yet. The best way to deal with this is likely to be to split the client population between new users and old users, and migrate them incrementally from one pool to the next as more servers are upgraded and can cope with new increased new client pool membership. This can be done with specialised proxies or load balancers in front of the main application servers and can be signalled in a number of ways, such as by returning a cookie that indicates which pool the client is currently a member of. Each new request will continue to state which pool the client is a member of, allowing it to be pinned to the upgraded set of servers. Alternatively, the transition could be made based on other identifying data such as ranges of client IP addresses.
Best Practice 18: Clients should support cookies, or a similar mechanism
Best Practice 19: Services should keep track of whether a client should be pinned to old servers or new servers during an upgrade using cookies, or a similar mechanism
Replacing Resources or Capabilities
Often as a URI space grows to meet changing demands, it will need to be substantially redesigned. When this occurs we will want to tear up the old URLs and cleanly lay down the new ones. However, we're still stuck with those old clients bugging us to deal with their requests. We still have to support them or automatically migrate them. The most straightforward way to do this is with redirection.
Best Practice 20: Clients should follow redirection status responses from the server, even when they are not in response HEAD or GET requests
Best Practice 21: When redesigning a URL space, ensure that new URLs exist that have the same semantics as old URLs, and redirect from old to new.
RFC2616 has some unfortunate wording that says clients MUST NOT follow redirection responses unless the request was HEAD or GET. This is harmful and wrong. If the server redirects to a URL that doesn't have the same semantics as the old URL then you have the right to bash their door in an demand an apology, but this redirection feature is the only feature that exists for automated clients to continue working across reorganisations of the URI space. It it madness for the standard to try and step in and stop such a useful feature from working.
By supporting all of the 2616 redirection codes, clients ensure that they offer the server full support in migrating from old to new URI spaces.
Conclusion
I have outlined some of the key best practice items for dealing with API changes in a forwards-compatible and backwards-compatible way for methods, media types, and specific service contracts. I have not covered the actual content of these protocol elements, which depend on other abstraction principles to minimise coupling and avoid the need for interface change. If there is anything you feel I have missed at this technical level, please leave a comment. At some stage I'll probably get around to including any glaring omissions into the main article text.
Thanks guys!
Benjamin