Service-orientation is a discipline within computer science that seeks to maximise business value firstly by encapsulating reusable logic and data within well-defined and easily accessible services, and then secondly by actually reusing these services. A service-oriented architecture distinguishes between logic that will not be reused (application logic) from logic that is reusable (service logic). Service logic is reused from application to application as business needs change to avoid reinvention of the wheel, reduce time to market for new applications, reduce the maintenance costs associated with having redundant implementations of reusable logic, and increase the return on investment of reusable logic by amortising costs over a series of applications.
Service-orientation is set up in opposition to traditional silo mentalities of software development where application development teams do not talk to each other across an organisation and where each new application is built up often completely from scratch based on whatever third-party or language framework tools are available.
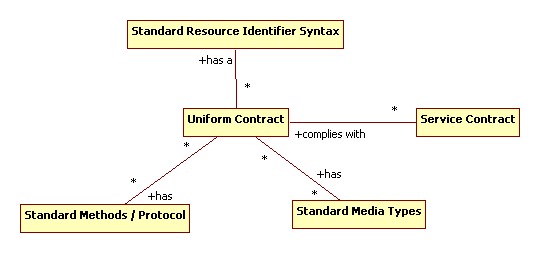
A major focus of the REST architectural style is on building a uniform contract that decouples services from their consumers, decoupling consumers from individual service contracts. What service-oriented folks see as loose coupling "I'm depending on a service's contract, but I have abstracted it to a degree where the service is able to evolve and even change technology foundations without breaking the contract", REST folk see as tight coupling "Your consumer can only talk to a single service?? You have to rewrite your consumer each time you swap one business for another within your supply chain??".
REST would have us depend only on a uniform contract in order to access the capabilities of a service. Consumers at design time should not know the details of any particular service contract. Instead, they should be written against the uniform contract based on a generic conceptualisation of the capabilities a service might offer.
The classic example of this approach can be found in the Web browser. A user types in a browser address, then navigates from page to page regardless of what service is being offered. The browser doesn't have to be rewritten in order to navigate from yahoo to google, or from facebook to the library of congress. Defining a uniform contract means that the technology part of the equation - the web browser - is able to interact correctly with whatever it is directed to interact with. If the browser knew the contract of the services it was dealing with ahead of time it would become tightly coupled to these services and browsing as we know it would end.
But let's take another look at this vision of browsing. Some REST proponents would suggest that we have eliminated the service contract in this model. We have substituted it for a reusable uniform contract shared by all services on the Web. I disagree with this notion entirely, and say that the service contract remains. It is captured in the individual unqiue sets of URLs each service offers that expose its service capabilities. "getGoogleSearchForm(): SearchForm" has simply been substituted for "GET https://google.com/: text/html". The same underlying capability continues to exist and still has a unique form of addressing available to invoke it.
We can take this view further: Say that I deduce from the form that I can submit a query of "GET https://google.com/search?q=test", what would happen if this resource stopped working or changed its semantics? Well, my operation certainly wouldn't work. This is a contract that if broken will have significant impacts on service consumers. This is the service contract.
So we can take a step back, and say that while service contracts still exist in REST we discover these at runtime. Service consumers don't hard-code knowledge of these capabilities at design time, do they?
Well, in some cases they do. Web browsers these days will almost certainly be hard-coded with knowledge of the URL they need to upgrade themselves when they are out of date. When a web browser is installed on my computer it is almost certainly going to have a "home page" and a set of default bookmarks to access. In fact, quite a bit of contract information is built into a web browser at design time. Much of this can be tailored or replaced at runtime, but nevertheless it is there.
It is this observation that is perhaps most powerful in determining how we should publish the contracts of our RESTful services, and how consumers that are more automated than a typical web browser should discover services and their contract. Discovery of services by developers of automated consumers is critical to the goals of service-orientation in achieving actual reuse of service logic. If the developer of a new application is unable to discover existing service logic and learn effectively how to use it then it is doomed to be reinvented and the silo mentalities continue within your organisation.

The figure above shows a basic model for discovering services within a REST context. We start out with the publication of each service's contract. This is essential in order to achieve reuse of service logic. This doesn't necessarily have to be the whole contract, but has to be sufficient for any service consumer that is previously unequipped with service URLs to discover any other URLs it may need to access over its application lifespan. Key elements of the published service contract for each service capability will be:
- The uniform contract method that will be used to invoke the service capability (e.g. GET or PUT)
- The URI Template to be used in invoking the capability (e.g. https://google.com/search?q={query} or https://soundadvice.id.au/)
- The uniform contract media type alternatives that are supported for the capability (e.g. text/html or application/vnd.com.example.invoice+xml). Multiple alternatives may be present, using content negotiation to select the most appropriate form for information exchange in any given interaction
- Sufficient human-readable semantic information for the application developer to understand the capability and validate it as applicable to their needs
The next step is performed by the application developer. The developer would scan a registry of services and related capabilities in order to find one or more that will reduce the cost of developing their application.
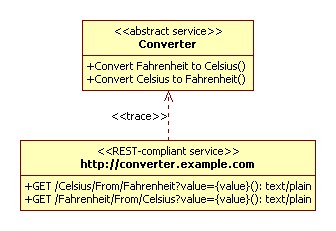
Steps 3 and 4 can occur in parallel. (3) is reasonably easy to understand. It is figuring out how to use the uniform contract correctly within the service consumer. In a perfect RESTful world this might be the only step between these two that we would take. It involves studying the specifications for uniform contract elements used by this service and determining how to build the logic of the service consumer based on these specifications. If we find a blog service we might determine that we are going to use GET requests to the service's URLs and make sure we are able to process application/atom+xml responses in return. We might choose to understand a subset of link types in order to discover related URLs and do things like fetch the contents of podcasts and vodcasts on behalf of our user.
By depending only on the uniform contract while determining these key details we are able to remain loosely coupled with the service we initially discovered. If another service happens to reuse those same uniform contract details our consumer can use the capabilities of that other service without needing to change its logic at all. It just needs to select different URLs to go and interact with. When our consumer follows those links it knows how to understand it doesn't care what service is actually offering the links. It just navigates from resource to resource using the uniform contract as its guide as to how to interact correctly.
Step (4) kicks in wherever the uniform contract detail is insufficient to base our service consumer upon. Typically this step does not specify how to build the logic of the service consumer, as step (3) did. Instead, it defines what the configuration file for our service consumer will look like. It preconfigures the consumer with a set of resource identifiers, and sufficient semantics to figure out what to do with these configured URLs. Typical web browser examples include "home page" - the page you open when you start. "bookmarks" - the links and titles to put in the bookmark folder for the user to select. In a more automated world these URLs might be attached to semantics such as "source of data for your reports", "resource to check to see whether operation xxx is permitted", or "place to store to when you want to launch your nuclear missiles". The semantics of these URLs embedded within the configuration file are abstractions of the semantics of the service contracts they came from. The more of an abstraction from the service contract, the more loosely coupled this service consumer will be from the service. In REST we are seeking to minimise this coupling wherever it could appear, and maximise dependency on uniform contract elements instead.
When we have completed (3) and (4) we move on to implementing the service consumer. We should be able do this based on the briefs produced in analysing the service contract and its related uniform contract elements. Developers of the service consumer should not have directly reference the service contract itself. They should especially avoid embedding specific URLs or URL templates that have not been through some process of review and abstraction prior to implementation. In a REST-style SOA services are discoverable, but consumers are able to freely navigate and be reconfigured to interact with the capabilities of other services as required.
Benjamin