


What should a client implementation of a REST interface look like in order to take full advantage of the evolutionary mechanisms built into REST directly and more broadly into the Web? More importantly, how should clients be written to best benefit the architecture as a whole and permit gradual evolution of both media types and resource identifiers? I thought I would put a few words together to specify what this should all look like.
A Single Asychronous Request
I'm going to position this specification in terms of an asychronous request that a client wishes to issue to a server. If you prefer, you can think of this as a single asynchronous request that a service consumer issues to a service. From a SOA perspective some base part of the URL (often the authority of the URL) will identify the service. Anything past that point is a fine-grained identifier for a resource the service owns, and each resource presents a uniform interface consisting of media types only from the centralised schema inventory and methods only from the centralised method inventory.
I am framing this in terms of a class that models a single request because I want to be clear what should generally be a responsibility of calling code versus what should be handled automatically and efficiently by the REST client framework. This single request should be essentially as easy to invoke as any capability of a SOA service, and just as easy to understand despite the magic.
Objectives
The main objectives of this class are to correctly handle retries, redirection, and content negotiation. Data folding is also a potential bonus. Retries allow for reliably issuing requests, but are only appropriate for idempotent and safe requests. Redirection allows the set of resource identifiers in the architecture to evolve over time as services are upgraded without requiring client upgrade. Content negotiation allows services and their consumers to be upgraded independently without breaking compatibility with each other as particular media types are deprecated and eventually phased out over the lifetime of the architecture.
These are all features designed to support run-time discovery of resources (known as hyperlinking) and therefore run-time discovery of services by clients. This discoverability is designed to continue working over the lifetime of the architecture without requiring mass-redeployment or mass-reconfiguration of components. Each component continues to do its job, following and directing clients to follow links as required, and stating its own capabilities to the extent necessary for components around them both old and new to continue interoperating with them.
A Simple Class
Let's assume that we have a HTTP implementation that is able to make individual requests on our behalf. I say HTTP not because it is the only RESTful protocol, but because it is a common and reasonably exemplary one. It incorporates many features from Roy's specification alongside a few Web-specific features.
The class we will look at initially covers most of our objectives. It will deal with retry, redirection and data folding. I will leave content negotiation for an advanced version of the class.
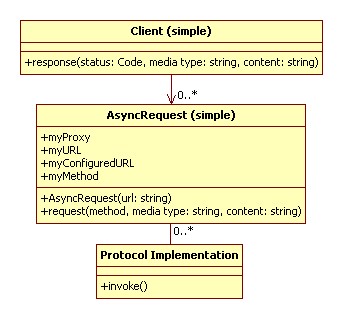
This at first looks simple: As a client object, you construct an AsyncRequest with the URL of your resource. Once constructed you invoke a request with the required method, plus an optional media type and content to send with the message. Media type and content can both be treated as strings (or byte arrays) and would be the body of a HTTP request. Method is probably a simple string, but more complex requests might require the inclusion of additional header information.
When the response is received, AsyncRequest will invoke a callback on the client. Code is probably a numeric HTTP code, however it should at least be easily convertible into an easy success/fail status and as with method may have associated headers. You might use a code class that can return this information from a function for easy synthesis while retaining the ability to log full response details for analysis in the case of failure. Media type and content are again strings or byte arrays, and have the same semantics as they do in requests.
Behaviour
The AsyncRequest class will attempt to make its request to the service over a TCP transport. Failures in the transport can be modelled as HTTP response codes. Failure to connect can be modelled as 503 Service Unavailable, as the request is known not to have been processed. Failure after connection can be modelled as 504 Gateway Timeout, where it cannot be discerned whether the request was processed or not.
On initial construction, myURL and myConfiguredURL are both set to the specified URL. myProxy is cleared unless an explicit proxy is configured. The myURL value normally determines which DNS name or IP address to connect to at the TCP level. However, this is overridden by myProxy if it is present. The myURL value is sent as part of each request, including retries. myURL and myProxy may be modified by temporary redirection codes, while myConfiguredURL is only modified in the case of permanent redirection. At the end of any failed or successful request myURL is set back to myConfiguredURL and myProxy is either cleared or returned to a configured value.
Various HTTP response demand different action. These are return (success or fail), retry, modify and retry, sleep and retry.
| Code | Action |
|---|---|
| 100 Continue | Continue request - only returned if Expect: Continue was in request |
| 101 Switching Protocols | Continue request - only returned if an Upgrade header was in request |
| 1xx Other Informational | Return, failure |
| 200 OK | Return, success |
| 201 Created | Return, success (include location header) |
| 202 Accepted | Return, success (so far) |
| 2xx Other Successful | Return, success |
| 300 Multiple Choices | Return, failure (no mechanism exists to support this code) |
| 301 Moved Permanently | Modify myURL and myConfiguredURL to match Location header and retry |
| 302 Found | Modify myURL only to match Location header and retry |
| 303 See Other | Modify myURL only to match Location header, set myMethod to GET, and retry |
| 304 Not Modified | Return, success |
| 305 Use Proxy | Modify myProxy only to match Location header and retry |
| 307 Temporary Redirect | Modify myURL only to match Location header and retry |
| 3xx Other Successful | Return, failure |
| 400 Bad Request | Return, failure |
| 401 Unauthorised | Return, failure (you should almost certainly be using SSL if authentication is important, although use of a special class to handle challenges could be implemented) |
| 404 Not Found | Return, success if request was DELETE otherwise failure |
| 408 Request Timeout | Retry |
| 410 Gone | Return, success if request was DELETE otherwise failure |
| 416 Requested Range Not Satisfiable | Modify Range header according to Content-Range header and retry |
| 417 Expectation Failed | Drop expectation if possible and retry, otherwise return failure |
| 4xx Other Client Error | Return, failure |
| 500 Internal Server Error | Return, failure |
| 503 Service Unavailable | Sleep for indicated time and retry |
| 504 Gateway Timeout | Retry if request is safe (GET) or idempotent (PUT or DELETE). Otherwise, return failure. |
| 5xx Other Server Error | Return, failure |
The handling of these codes requires some rewriting and retrying of requests, and also potential sleeps. However, this can be handled transparently by the AsyncRequest class for the most part and the client does not have to be concerned. This can all happen behind the scenes, and therefore consistently across different clients and services to benefit the overall flexibility and evolution of the architecture.
Data folding is the concept that it is beneficial to miss intermediate states in favour of a correct current state. Data folding for GET requests relies somewhat on the class using this request, still. They would generally start the first request, then if they decide they need another request would note this fact for themselves while waiting for the response. If yet another need to send a request popped up while the first is outstanding, it does not need to be noted. The client will send its queued GET request as soon as the current one returns. We generally don't want to cancel a GET request in this context in case we get ourselves in an infernal loop of continuously cancelling requests while they are still outstanding.
Data folding also applies to PUT and DELETE requests, each of which is designed to completely replace the effect of the previous request on the same resource. As such, if we have a PUT or DELETE request in progress and another comes in we can simply queue the latest of these requests for a given URL. This allows us to convey our latest intent for the state of a resource without unnecessary delay attributable to intermediate states.
Through both of these data folding techniques we are removing unnecessary queuing within the architecture that can lead to increased system latency and eventual system meltdown. In fact, simply through the use of an object to model the request state we can easily keep track of how many of these objects and their corresponding requests we currently have outstanding and keep this queue under control as well. Data folding support can be wrapped up in its own class for the convenience of clients, or possibly even into the main request class.
Adding content negotiation
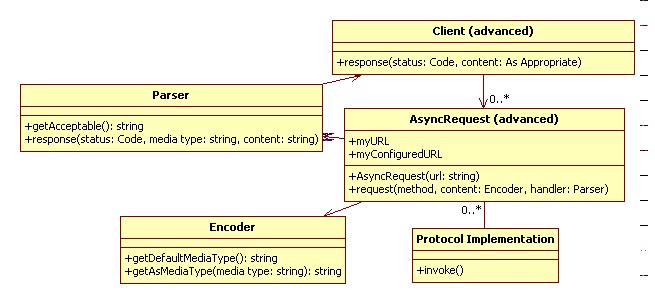
In order to correctly support content negotiation we must give over our content to the AsyncRequest class in an encoding-neutral form. I have shown this as an abstract class in the above diagram called "Encoder". What this does is allow request content such as that from a PUT to be encoded as several possible media types. A default is typically selected and the content encoded in that form for transmission. However, if this type is not acceptable to the server we will hopefully get back enough information to retry the encoding with an acceptable type. An example where this kind of thing would be useful would be for an architecture transitioning from RSS to atom news feeds. An upgraded client may try to PUT an atom article to its server, but the server only accepts RSS. The server rejects the initial PUT request (perhaps with some expect-continue going on behind the scenes) and informs us (hopefully through an Accept header in the response or similar) that it does support rss. We ask our encoder to format the document in the legacy RSS form, and can continue our operation to a success state.
On the return side we have a Parser class to interpret responses. Its set of acceptable types is first interrogated as we send a request, and this information included for transmission to the server. A correctly-implemented server will return us a document in one of the acceptable types, and that document will be passed through the Parser on its way back to the advanced client. The client cares only about the information contained in the document, not in the encoding format. Therefore, the content is parsed into a common data structure appropriate for Client processing.
This picture is a little more complicated than the simple picture described previously, and could be simplified slightly. For example, the Client could incorporate Parser and pass its list of acceptable types directly into the AsyncRequest request method. However even in this structure it is likely that you would want to separate out the parser code so that it could be used by multiple clients that share the same required data structure. This is particularly the case for very simple types such as numbers and strings that may be able to be easily extracted from a number of different media types.
Conclusion
The important features of HTTP in support of REST architectural constraints and objectives should be implemented consistently across all HTTP clients. The architecture as a whole suffers if they are missing or difficult to use as evolution requires simultaneous upgrade of multiple components. Supporting redirection and content negotiation at the very least, plus sleeping when a service is under load and observing other responses means that we are more flexible in how we can modify and operate our systems both large and small.
A key to success in this area is to make the client implementation as simple as possible, and really zero additional effort to support these features. A good interface design in this area can lead to better architectural outcomes.
Benjamin