I want to make clear at the outset that I am not an expert in 4+1. I have
spent the last few months working with systems engineers on an Australian rail
project, and this is the sum total of my systems engineering experience. I am
reasonably happy with my understanding of both concepts as they apply to my
specific situation, but this approach my not apply to your problem domain.
I am using
StarUML
for my modelling, and this pushes the solution space in certain directions.
2008-09-08: So that was then, and this is now. What would I change after having
a months to reflect? Well, I think it depends on what you are trying to get
out of your modelling. The approach I initially outlined is probably OK if
you are trying to cover all bases and get a lot of detail. However, now we
might step back into the product space for a while. What we want to do is
get away from the detail. We want to simply communicate the high level concepts
clearly.
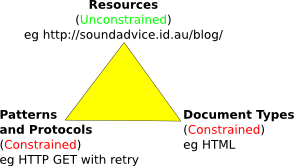
Overview
The first view of the
4+1 model
for architectural descriptions is the
Logical View. A classical computer science or software engineering background
may not be a good preparation for work on this view. It has its roots more in
a systems engineering approach. The purpose of this view is to elaborate on
the set of requirements in a ways that encourages clear identification of
logical functions, and also identifies interfaces to other systems or
subsystems.
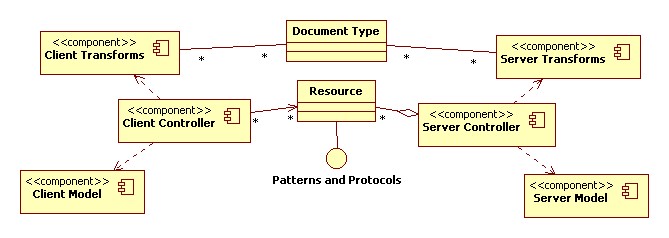
The general approach that I have been using for this view is a combination
of
data flow
and
robustness
diagrams. The elements in these diagramming techniques are similar,
but both are constrained in my approach to serve separate specific purposes.
Robustness diagrams are drawn by working through an input requirements
specification. Out of this process "functions" are discovered and added to a
functional data flow diagram. Finally, a context diagram is constructed as an
extraction from and elaboration on the function data flow diagram with external
systems identified.
Interfaces are identified at every stage through this process, including
Human-Machine Interfaces. The structure of robustness diagrams make it
relatively simple to identify missing interfaces and other gaps in the
analysis. The interfaces identified are reflected in the following Process
View.
The first thing I would change here is that I would split the concept of a
4+1 Logical View and the systems engineering -style functions diagram. The
second thing I have been doing has been to try and limit my content to a single
diagram. I'm trying to contain the urge to reach for crinkly goodness in favour
of saying "just enough".
Context and Function Data Flow Diagrams
Data Flow Diagrams are very simple beasts, made simpler by the constraints
I apply. For the purpose of identifying functions we use only circles for
functions, and directed associations for data flows. Other features such as
data sets or identified interfaces are banned in the function and context
data flow diagrams. Data flows are labelled with the kind of data being
transferred, and functions or systems are named.
Some guidelines for the definition of functions:
- An interface is not a function. You should not be able to draw a function
that has the same name on an "in" data flow as it has on an "out" data flow.
- Configuration data and HMI are part of a function, not functions in their
own right. We are setting out to describe the behaviour of the system in its
completed state, not to design the system in this view.
- Non-functional requirements are implicit in this view. Don't try to draw
these. This view may even help you distinguish between functional and
non-functional requirements. Non-functional requirements and functions that
are separate from their configuration data will want to be involved with every
function and every control. Functional requirements, much less so. We are
trying to come up with a set of functions and functional interfaces in order to
maximise functional cohesion and minimise coupling.
However, again we are not designing the system. The design in later views will
follow the lines of these functions, and will elaborate upon them with solutions
to non-functional problems.
- Functions are not use cases, nor necessarily collections of use cases. A
use case can span multiple functions. A function is a cohesive set of
requirements that is further elaborated in its robustness diagram or diagrams.
- The border between adjacent functions is always a data flow, never a control flow.
The set of functions should describe the system as the user sees it, rather
than how it is built. The data flow diagrams describe relationships between
systems or functions, not between software or hardware components. As
additional constraints on these data flow diagrams I do not allow the
expression of data stores at this level. They are described in the Robustness
diagrams where necessary. This level is purely about flows of data between
units of behaviour.
The flows do not discriminate between REST-style, database-style,
API-style, or any other style of interface. How the interface itself is
expressed is a design decision.
Unfortunately, I was on crack when I wrote some of this. In particular,
I have the concept of functions almost completely backwards. What I ended up
calling functions are more like subsystems and... well.. you get it. I have
since been corrected in a number of areas.
Here is how I would draw the robustness diagram today:

The context diagram remains the same, and I would continue to include it.
I have started to prefer describing interfaces in terms of the information
they communicate rather than trying to preemptively name and collate them based
on other factors.

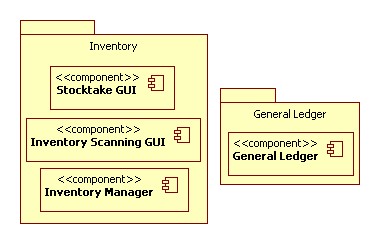
Here is a functions diagram, where I have collected the functions back
down into a single figure. The key interfaces are still present, and I have
two basic sets of data in the system. I have the ledger data, which is based
on pure accounting principles. The other data is the historic share prices.
The share prices are acquired and stored based on live stock quotes.
This information is combined with ledger-based accounts data for the shares
investments in order to generate appropriate reports.
Other sources of data for accounts include the daily sales ledger acquired
from the Point of Sale system, internal movement of warehouse stock, and
input from stocktake operations.
Per-function Robustness Diagrams
Robustness diagrams consist of boundaries, entities and controls. Boundaries
are interfaces to your system, including Human-Machine Interfaces. These are
functional interfaces, so typically identify broadly the kind of information
required or the kind of control exerted through the boundary. The set of
boundaries may be refined over subsequent iterations of the logical view, but
do not be concerned if they do not line up exactly with the set you expected.
Multiple functional HMI boundaries may be combined into one user interface to
provide the best user experience. Multiple software or protocol interface
boundaries may be described in a single Interface Control Document.
The process of building up the functions involves reading through
requirements one at a time. Look for vocabulary in the requirements that suggest
a system boundary or entity. A single requirement may appear as an entity in
your diagram, or many requirements may map to a single entity. Only
a poorly-written requirement should require multiple controls to be associated
with it. Entities are identified when one requirement talks about producing
some kind of data to be used by another. An entity is a set of data, such as
a database. We are not trying to build an Entity-Relationship model (I draw
entity relationships outside of the main 4+1 views). Once the data set is
identified it is not elaborated further in this view. An entity may be
temporary or permanent data.
Some guidelines for the Robustness Diagram
- Controls bind everything together. Boundaries do not touch boundaries or
entities. Entities do not touch entities. A control must be present between
these end-points.
- Don't try to chain too many controls together. In general I would expect
only a simple flow from one or more boundaries or entities through a control to
one or more boundaries or entities. Requirements-mandated validation behaviour
is a common exception to the rule, where the validation is subservient to a
main control. It is especially useful to do this if the validation interacts
with a different set of boundaries and entities to the main control. However,
don't attempt to describe an algorithm by linking controls together.
- Don't go overboard with entities, controls, or boundaries. If your diagram
has the same controls always operating on two different entities or boundaries,
they may need to be collapsed into a single entity or boundary. If two similar
controls are relating the same set of entities and boundaries, consider
collapsing them into a combined control. The main goal is to establish how
concepts from the requirements specification are related by behaviour. The
requirements themselves are still there to describe the behaviour in detail.
- Be suspicious of a control that is not driven from anywhere, and entities
that influence behaviour without obvious input. Look for missing functional
HMIs and other unidentified system boundaries.
- Don't try to make every requirement a control. Many requirements are there
to clarify or constrain a general functional behaviour. The goal of controls
in these diagrams is to capture specific uses in order to bind the concepts
held in boundaries and entities functionally together. We thereby discover
the functionality required of known boundaries, as well as possible missing
boundaries and implied behaviours.
- As entities are data, they are candidate points for splitting a large
robustness diagram into multiple functions with a data flow between. However,
avoid splitting cohesive controls apart unnecessarily. Try to describe a
logical set of behaviour in a single diagram and as a single function.
- Robustness diagrams are not use cases, and are not collaboration diagrams.
Directed associations can be useful in showing control flow from start entity
or boundary through controls to their destination. However, ordering is not
implied, nor is frequency or method of control flow. The level of granularity
of these diagrams only allows us to say something like: "When data changes
across this interface or in this entity, this kind of behaviour will happen
involving these other boundaries and entities".
- Do not try to identify functions in the robustness diagrams themselves.
Functions and controls are different concepts. Functions are behaviour with
information exchange with the next function. Controls are behaviour that pass
control flow to other controls and update entities or boundaries.
- Do not design internal structure into the system.
Boundaries are system boundaries, not function boundaries. Entities
are identified naturally as domain concepts out of requirements.
They are not invented.
This is where I would really start to split from my original description
of the Logical View, and move closer to what Phillipe originally suggested.
That is, an object-oriented approach. We design a set of classes that we
would implement if we didn't have to worry about any of the details. We
wouldn't worry about redundancy. We wouldn't worry about performance. We
wouldn't worry about client/server separations that might be present in the
real system. This is an idealised software-centric view of the solution.
Example
The example I am using is of a very simple accounting system. I haven't
written up formal requirements, but let us assume that the following model
is based on a reasonable set. I will work though this example top-down,
generally the opposite direction to the direction the model would have been
constructed. The source model can be found
here (gunzip before opening in StarUML).

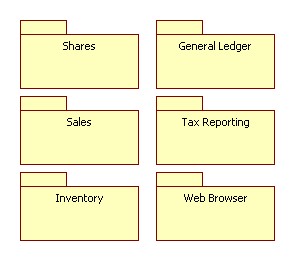
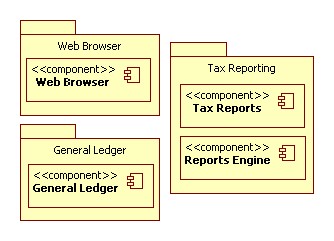
The context diagram shows the Accounts system in context with an adjacent
Point Of Sale System to acquire a daily sales ledger, and a broker system to
provide live stock quotes. If I were presenting this in a formal document I
would re-draw it in visio. Packages would be drawn as "function" circles,
and interfaces would be removed (leaving only data flows). Since we are all
friends, however, I'll leave it in the model form for the purpose of this
entry.
Already we can see potential gaps. We get live stock quotes from the
broker's system, but no buy or sell orders. Is this intentional, and the
buy/sell orders are handled entirely within the Broker System or have we
missed it from our analysis?

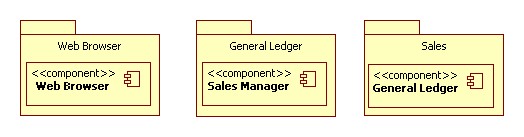
The set of identified functions tracks these external interfaces down to a
lower level. The stock quotes from that broker system are being fed into a
shares investing function. Sales receives the daily sales ledgers. Inventory
is a self-contained function within the system. Tax Reporting uses data from
all of these functions.
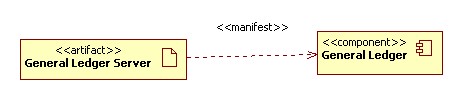
It is possible that a general ledger function could appear at this level,
but so far in this analysis we have not determined the need for it. The system
is used for shares investing, sales and inventory tracking. Any general ledger
containing the combined records of all of these activities is a design decision
at this stage. Tax reporting requires that we bring the data together in some
form, but whether we mine it directly or convert for easy access remains
unconstrained by this logical systems engineering process.

The Sales function has two main controls: To import the daily sales ledger
from the POS System, and to generate reports. A historical sales ledger entity
naturally appears out of this interplay, and becomes the boundary between this
function and the Tax Reporting function. We discover a HMI is required to
request report generation. Does this HMI need to do anything else? Is printing
required? If so, do we need to be able to cancel print jobs? Are these
functions of the system?

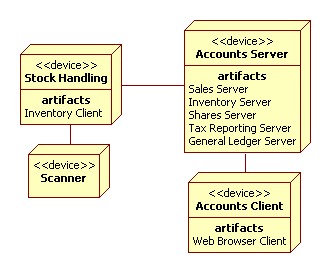
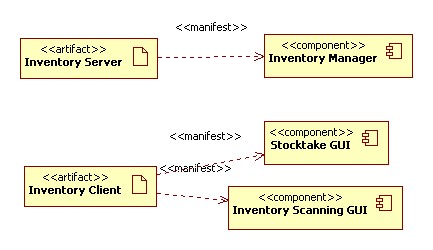
The Inventory Function has four controls. Two are relating to scanning stock
in and out of stores. Another two are related to stock-take. Stock is re-scanned
and compared against Inventory. Once all stock is scanned, the Stocktake HMI
accounts for any shrinkage. Both the Inventory Scanning and Stocktake HMIs
can take a number of forms. There might be keyboard and VDU entry. With any
luck there will be a bar code or rfid scanner in the mix. The same scanner
might be used as part of both HMIs, and both HMIs may be combined into the one
end user HMI.

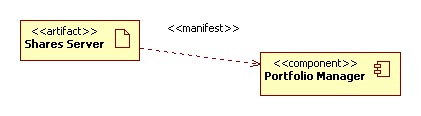
Investment Tracking involves recording of purchase and sales of stocks. We
can run reports based on the book value of these stocks (ie, how much we paid
for them), or based on their current market value. In order to do the latter
we need to keep a historical record of stock prices. Maintenance of this record
has a clear entity boundary at Historical Stock Prices that makes it a
candidate for separation into a new
function. We still might do that if this function becomes unruly. I have placed
a kind of stub interface in here for periodic execution of stock quote updates.
However, this obviously needs more thought. Where is the HMI to control how
often these updates occur? Can they be triggered manually?

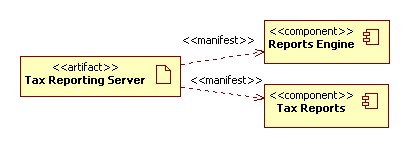
I foreshadowed that the entities from other functions are referred to
directly in the Tax Reporting robustness diagram, and here it is so. This does
not directly imply that the Tax Reporting function has access to the databases
of the other functions. It simply means that the set of information
(or relevant parts of that set) is transferred to the tax reporting function
at appropriate times. This could be by direct database access, by an ETL into
the tax reporting function's own database, by a RESTful data exchange, or by
some other means.
And this is how I would do it, now. This is a very basic diagram, but you
can see that it is software centric
in that it balances data with functionality, and views the world as a set of
classes and objects. I would generally start with an entity-relationship or a
class diagram relating to domain-specific vocabulary from the requirements
specification, and work from there.

To some extent I find this diagramming technique freeing. I don't have to
worry about the borderline between software and systems engineering. I don't
have to worry about components. I can just draw as I might have in my youth.
It will feel familiar to software developers, and a software developer should
be able to judge whether or not it works to convey the appropriate information.
Conclusion
The Logical View is somewhat airy-fairy, and the temptation is always there
to introduce elements of the design. Resist this temptation and you should end
up with a description that clearly separates constraints on your design and
design decisions you have made. The set of interfaces your system has with
other systems is a real constraint, so all of these interfaces appear here in
some form and behaviour required of those interfaces is identified.
You may need to round trip with the process view (and other views) in order to
fully finalise this view.
It is likely that the Logical View (especially its robustness diagrams) will
identify some inconsistency in vocabulary in your source requirements. It is
worth putting at least a draft of the design together before finalising
requirements for any development cycle.
I think that the context and function diagrams are quite useful in helping
flesh out the scope of a system as part of a software architecture. The
Object-Oriented nature of the real Logical View is a help to software
developers, and the description of the problem domain vocabulary in this
context should help stakeholders get a feel for how the system will address
their problems.
previous in series,
next in series
Benjamin