


Mark Baker recently wrote about about the difference between the best SOA pratices of today, and REST. I find it difficult to pin down authorative statements as to how the SOA architectural style is defined or best praticed, however Mark sees a gradual conformance to REST principles. He described the main outstanding issue as "generality". I think my considered answer would be "decoupling for evolvability".
I think the answer is a little more sophisticated and involved than "generality". As Stu Charlton notes:
Even old crusty component software had this concept (operations constrained & governed to maintain relevance across more than one agency) - Microsoft COM specified a slew of well-known interfaces in a variety of technical domains that you had to implement to be useful to others.
I made a similar note in the current REST Wikipedia article:
Uniform interfaces reduce the cost of client software by ensuring it is only written once, rather than once per application it has to deal with. Both REST and RPC designs may try to maximise the uniformity of the interface they expose by conforming to industry or global standards. In the RPC model these standards are primarily in the form of standard type definitions and standard choreography. In REST it is primarily the choice of standard content types and verbs that controls uniformity.
I think the real answer is held in how the REST Triangle of nouns, verbs, and content types allows different components of a protocol to evolve separately towards uniformity. We think of HTTP as a protocol, but it clearly does not capture the whole semantics of communication over the web. The full protocol includes a naming scheme, a set of verbs, a set of content types, and a transport protocol such as HTTP.
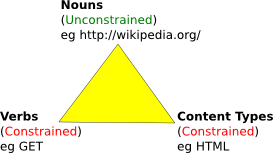
In current REST practice the accepted naming scheme is the URL, and the accepted verbs are basically GET, PUT, POST, DELETE. The current content types include html, svg, etc. However, Fielding's disseration defines none of these things. They are meant to each evolve independently over time, never reaching a time when the evolving architecture is "done".
If we contrast the REST view to classical base-class, arbitrary method, arbitrary parameter list object-orientation we can see a few differences. I think the main difference is that a classical base-class defines both the verbs of communication and the content types in one coupled interface. The REST approach is to determine separately which verbs are needed for universal communication and which content types are needed. This decoupling allows someone needing new semantics to be transferred between machines a significant lead up to defining the whole necessary protocol:
The naming system is well-defined and well-understood. No need to do anything there. The standard verbs are sufficient to operate any any virtualised state. Easy. So the only problem left is the definition of a content type to carry the semantics as a virtualisation of the state of your objects.
In REST, the protocol for delivering HTML documents to a user is closely related to the protocol for delivering images. The different protocols for delivering images (uri+verbs+svg, uri+verbs+png) are also closely related. Retaining the meaning of a verb between different content types and retaining the meaning of a content type across different verbs is a big leg up when it comes to innovation in the communications space.
Our software cannot communicate semantics unless our programmers agree with each other. This is an intensively social process involing politics of money, power, greed, personality, and even occasionally some technical issues. However, REST is about not having to start from scratch.
REST is about starting from a shared understanding of the noun-space, a shared understanding of the verb space, and a shared understanding of the content space. Whichever one of those has to evolve to support the new communication can be targetted specifically. It is easier to agree on what a particular document format should look like within the constraints of the classical verbs. It is easier to agree on how publish-subscribe semantics should be introduced within the constraints of the classical content types.
Stu also writes:
[U]niformity, as a technological constraint, is only possible in the context of social, poltiical, and economic circumstances. It's an ideal that so far is only is achievable in technological domains. HTTP, while applicable to a broad set of use cases, does not cover a significant number of other use cases that are critical to businesses. And HTTP over-relies on POST, which really pushes operational semantics into the content type, a requirement that is not in anybody's interest. In practice, we must identify business-relevant operations, constrain and govern interfaces to the extent that's possible in the current business, industry, and social circumstances, and attempt to map them to governed operations & identifiers -- whatever identifiers & operations are "standard enough" for your intended audience and scale.
And perhaps this is a point of confusion at the borderline of REST practice. REST advocates seem almost maniacal about uniformity and the use of standard methods and content types. I have highlighted lack of standard content-type usage in otherwise very precisely RESTful designs. REST has a hard borderline defined by its architectural constraints, and anything that falls outside of that borderline can be seen in black and white as simply "unRESTful". However it would be a fallicy to suggest that all software SHOULD be RESTful.
Most software on the ground will use a fair number of non-standard content types. There are simply too many local conventions that are not shared by the whole worldwide community for every exchanged document to become a standard. Applying as many RESTful principles as makes sense for your application is the right way to do it. As Roy pointed out in a recent rest-discuss post:
All of the REST constraints exist for a reason. The first thing you should do is determine what that reason is, and then see if it still applies to the system being designed. Use the old noggin -- that is the point.
REST is very strictly an architectural style for hypermedia systems crossing the scale of the Internet both on a technical and social level that allows for the construction of generic software components, in particular the generic browser. If your application does not involve developing a browser or your architecture is smaller than the scale of the Internet there are bound to be constraints that do not apply. You will still benefit by following the constraints that it makes sense to follow.
I find that following the constraints of a controlled set of verbs and content types over a uniform interface is extremely valuable even in a small software development group. Naturally, our set of controlled content types and even verbs does not exactly match up to those common on the web. Local conventions rule. However applying REST principles does make it easier to agree on what communication between our applications should look like.
It does make it possible to write a generic data browser. As local content types became stategically important we tend to look towards the wider organisation as for standardisation, and we sometimes aspire to standardation outside of the company and corporation. You could argue that until we reach that end-point we are only being nearly-RESTful rather than RESTful, but the benefits are there all the way along the curve. Perhaps the correct interpretation of Roy's use of the word "standard" in his thesis is that the verbs and content types are understood as widely as they need to be. This scope would typically differ between the verbs and content types. Agreement on the use and semantics of GET is required by a wider audience than is agreement on the use and semantics of svg.
Benjamin