

{kind=link}
Regular readers of my column will be familiar with a common theme: REST provides improved decoupling, evolvability and serendipitous reuse over unconstrained SOA. What you may not expect is a break from dense blocks of text into a world of diagrams (or at least a breaking up of dense blocks of text with diagrams). This article is on REST fundamentals. I'll start with a couple of version of the REST Triangle diagram I drew for Wikipedia a few years ago.
Dissecting a REST Triangle Instance

This diagram has a URL on the top point of the REST triangle, the URL of my blog. The left-hand points on the base refers to the HTTP operations GET, PUT and DELETE. The right-hand refers to various kinds of document that can be transported by HTTP: HTML, Plain Text, VJournal, and Atom.
You might notice while looking at this diagram that context decreases in clockwise direction around the triangle. Most of the meaning of an operation is held in its URL. You don't update someone else's blog when you PUT to my URL. You update mine. You won't retrieve stock quotes when you GET from my URL. You will only see my latest musings.
The types of transported documents are much more general than a single URL at my site. In fact, you can exchange HTML or Atom documents with a range of sites of differing natures around the World-Wide Web. However, there is a clear difference between HTML and Atom in terms of context. You will find Atom documents or documents expressible as atom at far fewer URLs than you will find documents expressible as HTML.
HTML is a low-jargon document type that allows text-intensive data to be rendered by a browser irrespective of its topic or context. It minimises coupling between client and server by avoiding being specific to a given purpose. However, in doing so it also gives up potential semantic riches. Atom is able to convey more interesting machine-readable semantics at the cost of being applicable to a smaller set of documents.
This is not an accident of either HTML or of Atom. I see a general case of friction between transferring high value semantics using specific vocabulary and jargonising communication so that it can only be understood within a restricted context. High value semantics generally increase coupling, and the only way to deal with this friction is to work the standards bodies hard to figure out what the world can and simply can't agree on. Matching vocabulary to context in a way that minimises jargon is the main practical challenge of any Semantic Web, a World-Wide Web that contains significant quantities of machine-usable information. Don't believe anyone that says building any kind of meta-model for data will make the semantic web happen. That isn't solving the problem.
The least content of all is held in HyperText Transfer Protocol operations such as GET. It simply means "transfer a document to me of a type I say I accept from the URL I specify". The Accept header and URL are what ensure useful data is transferred and that it can be parsed and interpreted by the client, becoming information. The GET operation is just there to make the bits move.
Generalising the REST Triangle
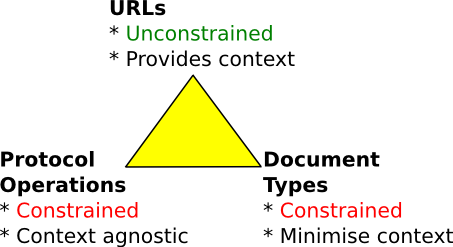
This second triangle diagram elaborates on and generalises the first. URLs are at the top providing context. Document Types are further clockwise; sympathetic to the context but minimising exposure to it in order to minimise coupling. Protocol Operations are furthest around the clock, and give only the barest nod to context.
The important thing about Document Types and Protocol Operations for what I am going to talk about next is that they are both constrained. If you don't control or can't list the methods in use within your system you are not doing REST yet. If you don't control or can't list the document types in use within your system you are not doing REST yet.
That second point can easily take people by surprise, especially when combined with a warning against "application/xml" or "application/rdf+xml" document types. A document type defines the information schema of a document and how that information is encoded as data. "application/xml" doesn't do that. I can give your application an XML document that contains exactly the information that it needs, but unless it is encoded in a way your application understands it remains simply data. If we are going to get serendipitous reuse you must understand my encodings whenever I transfer information to you that you should understand. We do that by controlling the set of document types in use and making sure that there aren't different encodings emerging gratuitously for the same thing. The other side of that coin is that whenever an application accepts a particular kind of information it should support all known encodings of that information.
So where do we go from here? The answer is REST Rewiring:
Building an Information Pipeline
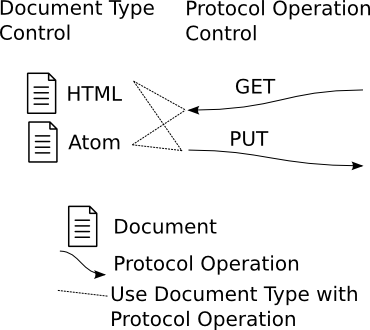
Here I show a GET and a PUT operation. Both transfer data at the client's request and on the client's authority, but do so in different directions. A GET transfers a document from URL (however that might be served) to Client. A PUT transfers a document from Client to a URL (however that might be interpreted). Any URL can deal with a GET or PUT if that operation is meaningful enough to have been implemented, and can reject the request with a reasonable response code otherwise. Stabilisation of these main document pipelines between clients and servers is the first prerequisite to most of the useful properties of REST.
The next thing to look at is what kinds of documents the pipelines are transferring. Remember our earlier discussion: The set of document types should be controlled such that the recipient understands that document type understands any information that could be meaningful to it. So not only is the document pipeline well understood, but the documents being transferred can be converted to information by any recipient for whom it is meaningful to have been sent the document.
By constraining Protocol Operations and Document Types we have produced an information pipeline, so what's left? Only to connect it to a specific URL.
Connecting up an Information Pipeline
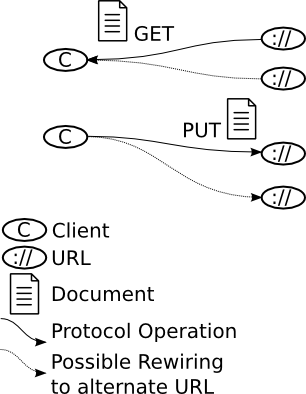
The information pipeline still has limited meaning outside of its context, and the URL provides this missing context. The client issued a GET request to a given URL, not because they could, but because a user wanted it to happen. Somewhere in the mix a user is configuring or driving a client to connect its information pipelines to specific URLs for information exchange. What is done with the information ultimately depends on the design of the recipient, which in turn depends on what the author and user decided the information was for.
Not to get too philosophical about it, but: The URL rounds out the meaning of the information transfer. The other aspects of communication, those making up the actual information pipeline, are relatively independent of the meaning of the transfer. More importantly, they don't get in the way when the user decides one day to connect the information pipeline to a different URL. Serendipitous reuse is the ability to reconnect information pipelines without gratuitous protocol differences getting in the way.
Getting out of the way of Communication
REST makes it the responsibility of the developer/architect to control the sets of methods and document types in use within an architecture. By doing so it makes life initially harder for the developer. They have to think about how to deliver services though the uniform interface of their architecture. Once thought though, serendipitous reuse follows (funny how serendipity always seems to follow hard work...).
This may seem like a fault in REST thinking, however look back to the problem of the Semantic Web. It isn't a technical problem. It can't be solved technically. The problem is not the technology, it is the lack of agreement between developers. So long as we are continuing to create different document types to convey the same or similar information there is no hope for machines to map one to the other quickly enough or accurately enough to match the expansion. What is needed is for the technology to move appropriate parts of the socio-technical problem back into the social space.
REST principles of are a socio-technical answer to building a Semantic Web, possibly the only one known to build a broad base for information exchange so far at scale.
Pipeline Evolution Paths
The World-Wide-Web doesn't stop at producing a socio-technical solution for building a static system. It goes on to provide evolution mechanisms for Protocol Operations (not implemented response codes, must-ignore headers, etc), for Document Types (must-ignore for unknown XML elements and attributes, content negotiation), and even for URLs (redirection). These facilities round out the solution in terms of the information architecture, providing long term evolution mechanisms.
Benjamin